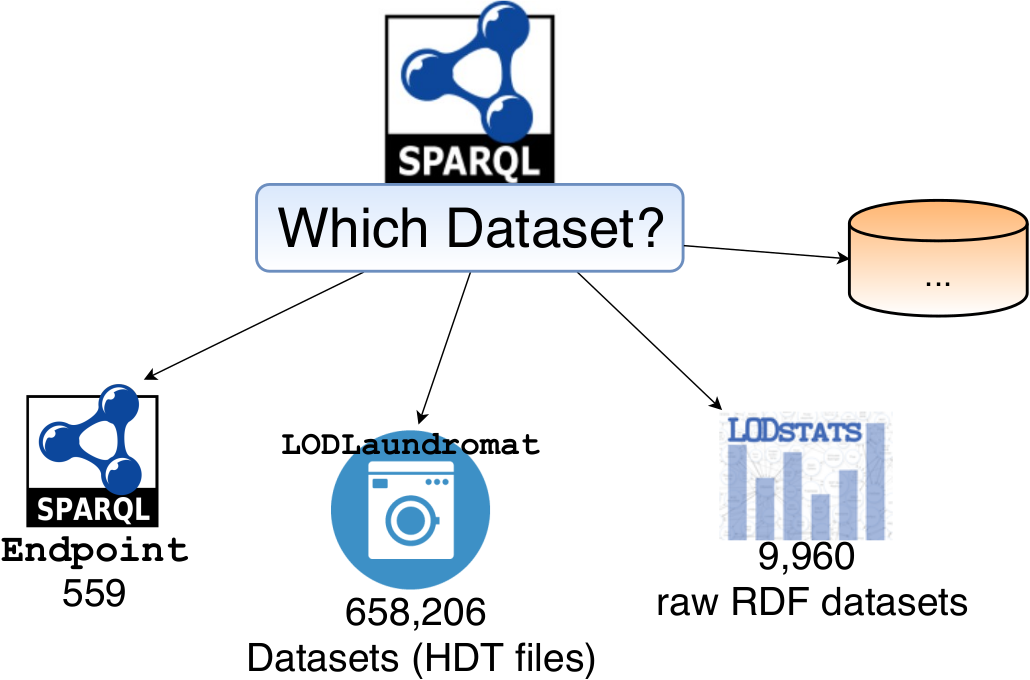
Over recent years, the Web of Data has grown significantly. Various interfaces such as LOD Stats, LOD Laundromat and SPARQL endpoints provide access to hundreds of thousands of RDF datasets, representing billions of facts. These datasets are available in different formats such as raw data dumps and HDT files, or directly accessible via SPARQL endpoints. Querying such a large amount of distributed data is particularly challenging and many of these datasets cannot be directly queried using the SPARQL query language.
In order to tackle these problems, We present WimuQ, an integrated query engine to execute SPARQL queries and retrieve results from a large amount of heterogeneous RDF data sources. Presently, WimuQ is able to execute both federated and non-federated SPARQL queries over a total of 668,166 datasets from LOD Stats and LOD Laundromat, as well as 559 active SPARQL endpoints. These data sources represent a total of 221.7 billion triples from more than 5 terabytes of information from datasets retrieved using the service “Where is My URI” (WIMU). Our evaluation of state-of-the-art real-data benchmarks shows that WimuQ retrieves more complete results for the benchmark queries.
The contributions of this work are:
- A hybrid SPARQL query-processing engine to execute SPARQL queries over a large amount of heterogeneous RDF data.
- Evaluation of real-world datasets using the state of the art of federated and non-federated query benchmarks (FedBench, LargeRDFBench and FEASIBLE).
- We present the first federated SPARQL query-processing engine that executes SPARQL queries over a total of 221.7 billion triples.
This is an ongoing work, in which the next step consists of a Large Scale approach to study the relation and similarity among the datasets. This work was supported by the Semantic Web group of HTWK Leipzig (https://www.htwk-leipzig.de/) under the advisement of Prof. Dr. rer. nat. Thomas Riechert.
Github repository: https://github.com/firmao/wimuT
Prototype/proof of concept: https://w3id.org/wimuq/
Slides: https://tinyurl.com/slidesKcap2019
Paper: https://dl.acm.org/citation.cfm?id=3364436
Conference: http://www.k-cap.org/2019/
Authors/Contact: valdestilhas@informatik.uni-leipzig.de, tsoru@informatik.uni-leipzig.de, saleem@informatik.uni-leipzig.de